It’s Time to Rethink Event Sourcing


I've always been fascinated by Event Sourcing (ES) and other Domain-Driven Design (DDD) concepts. At some point, I even built a prototype of an event-sourced system called LMAX, which handles 6M orders per second as a high-frequency trading platform.
Unfortunately, the traditional approach to implementing Event Sourcing comes with its own set of challenges. In this blog post, I’ll share new ideas on how to achieve 80% of the Event Sourcing benefits with 20% effort.
Why Use Event Sourcing
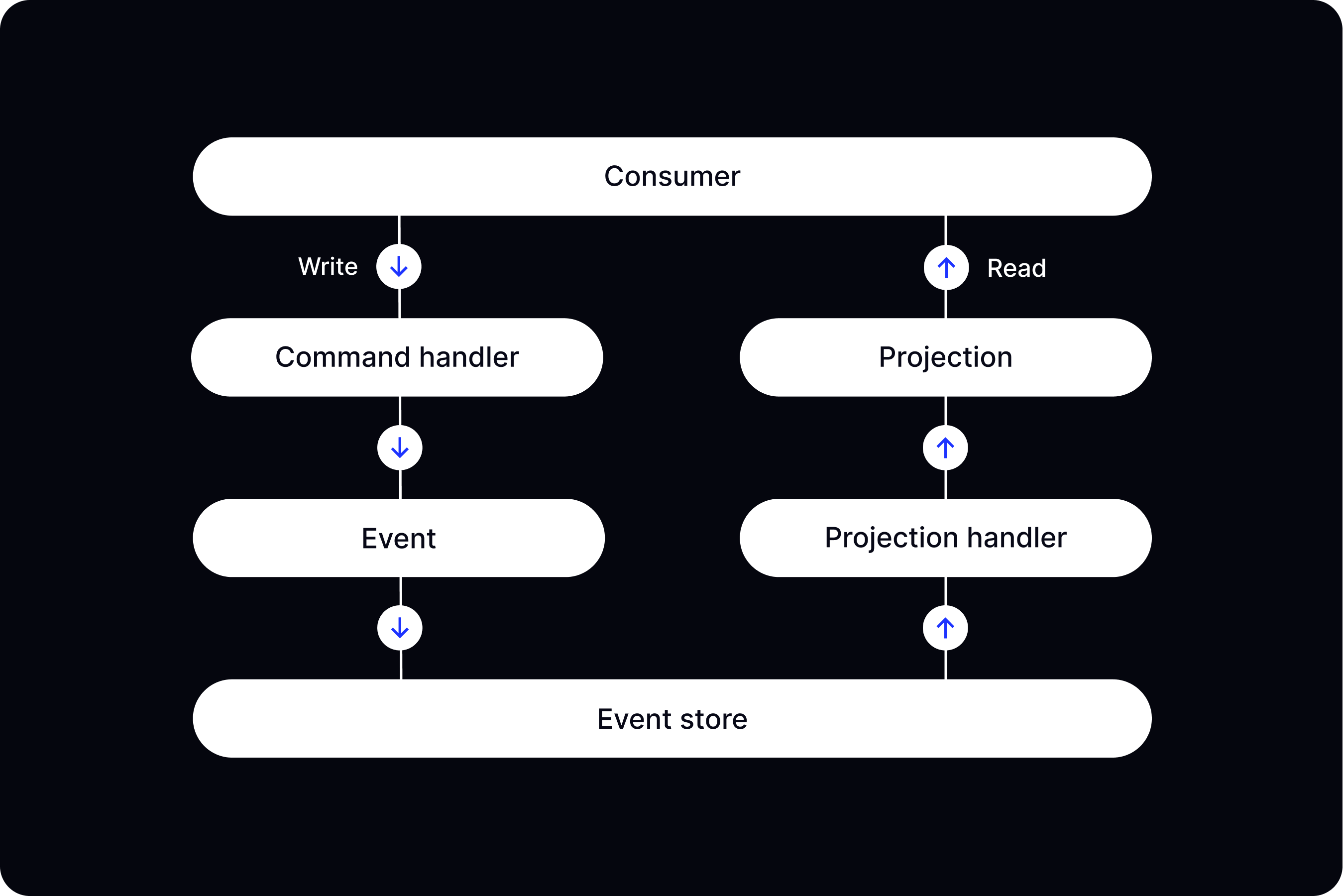
At its core, Event Sourcing is a simple architectural design pattern. All data changes are recorded as an immutable sequence of events in an append-only store, which becomes the main source of truth for application data. That’s it.
This design pattern provides many advantages:
- Data integrity. Unlike typical CRUD (Create/Read/Update/Delete) systems, stored events can’t be modified to ensure data integrity.
- Auditability. The append-only store of events represents an audit trail that make it easy to track and audit changes.
- Traceability. Events contain the context such as the ‘what’, ‘when’, ‘why’ and ‘who’, so you can easily trace and verify transactions.
- Compliance. Event store is a detailed log of all state changes, which is essential in regulated industries like finance, healthcare, etc.
- Rollbacks. If the current state is lost or corrupted, you can rebuild it by replaying the immutable events.
- Troubleshooting. The event store can be used for debugging and allows understanding the sequence of events leading to an issue.
- Time travel. Event Sourcing enables time travel capabilities by allowing you to reconstruct the previous state at any point in time.
- Enhanced analytics. It allows generating custom data representations (projections) to query historical data and identify patterns.
- Scalability and performance. Events can be handled asynchronously, which can improve performance and scalability.
Event Sourcing Examples
Most of us use existing event-sourced systems every day and can’t imagine living without them.
Bank ledger account
When you load information about your bank account, most online banks will show you recent ledger transactions, which represent event-sourced records of every money movement in your account.
The idea of recording ledgers as an Event Sourcing system was used way before computer systems were invented. Around 7000 years ago, ledgers were used to record lists of expenditures and goods traded on clay tablets, while temples were considered the banks of the time.

Version control system
Version control systems, such as Git, are examples of Event Sourcing systems. Commits represent code changes that are recorded sequentially and become the main source of truth.
Additionally, commits record information about ‘who’ made the change, ‘when’ the change happened, and ‘why’ it was made via a commit message.
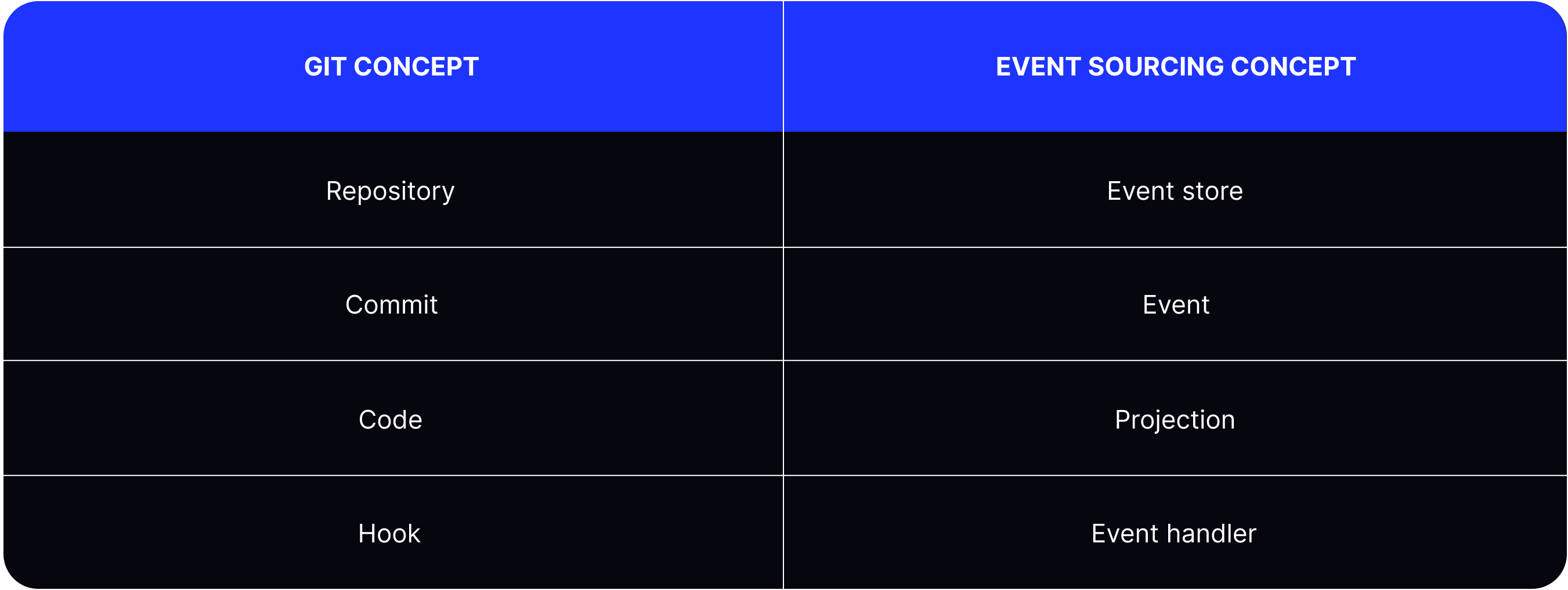
This means that you can view a history of all changes, time travel by checking to a previous commit, rollback changes, troubleshoot issues by using a binary search, analyze code changes, and so on. You’ve got the idea.
Issues with Traditional Event Sourcing
While Event Sourcing has many benefits, it also comes with many disadvantages that prevent it from being adopted more widely.
- Big paradigm shift. It is a fundamentally different approach to data management that goes against commonly techniques such as RESTful APIs and UPDATE/DELETE database operations.
- Extra dependencies. Implementing Event Sourcing usually requires introducing additional concepts, such as CQRS (Command and Query Responsibility Segregation), which need to handle events, take snapshots, and rebuild projections.
- Steep learning curve. Event Sourcing introduces new concepts and patterns that developers might not be familiar with, which can require additional time to adapt to the event-centric approach and learn new tools.
- Eventual consistency. Event processing at scale is generally done asynchronously, which requires rethinking how data is being accessed. For example, when a user submits a multi-step form, you won’t be able to show a summary with all saved information and will be required to just show a confirmation page in the UI instead.
- Event versioning. As your system evolves, you’d need to change the format of your events to, for example, start storing additional information. And because events are immutable, you’d need strategies for maintaining backwards compatibility or migrating old events.
- Storage and compute needs. Since all events are stored and never deleted, it requires more storage and compute resources, which typically involves implementing an event streaming system.
- Expensive migration. If you have a large non-event-sourced system, transitioning to Event Sourcing can be a significant undertaking that requires changing almost the entire codebase, backfilling past events, and careful testing.
- Upstart cost. There is lots of literature on Event Sourcing, but there are no universal and flexible frameworks that can work with any tech stack. That’s why most teams DIY and implement all additional code plumbing around commands, command handlers, validators, aggregates, and so on themselves.
Is there a way to get most of the Event Souring benefits while avoiding its disadvantages?
The New Approach to Event Sourcing
The disadvantages of Event Sourcing listed above make it a complete nonstarter for most companies. Let's reconsider the traditional Event Sourcing approach by taking a closer look at how we use a version control system like Git.

As you can see, with Git:
- We just reuse the existing tool for different projects without trying to invent a wheel.
- Continue editing and working with mutable code files instead of thinking how to construct diffs.
- Occasionally contextualize and wrap changes into commits, a higher-level standardized data abstraction.
- Get automatic state reconstruction that supports time traveling, rollbacks, and have a full audit log.
We can’t, however, blindly copy the Git model and apply it to build “Git for data”. The main reason is that Git commits are usually committed manually by developers, while data in applications is frequently changed automatically. Instead, we need to use a slightly different approach.
Change Data Capture, and its limitations
Change Data Capture (CDC) is a design pattern used to identify and capture changes made to data in a database in real-time. For example, when moving data from an online transaction processing (OLTP) database like PostgreSQL to an online analytical processing (OLAP) system like Snowflake, people typically use CDC to ingest changes and record them in a data warehouse.
{
"table": "shopping_cart_items",
"primary_key": 1,
"operation": "UPDATE",
"committed_at": "2024-09-01 17:09:15+00",
"before":{
"id": 1,
"quantity": 1,
...
},
"after":{
"id": 1,
"quantity": 2,
...
}
}Captured change
We could continue performing CRUD operations in a regular database (behaves like the latest snapshot) without rearchitecting our application, use CDC to capture all data changes in the background and store them as an immutable audit log (behaves like an event store).
There is, however, one big fundamental difference between Event Sourcing and Change Data Capture:
- Event Sourcing: Events reflect domain-related processes that happened at the application level. For example, “shopping item quantity increased”.
- Change Data Capture: Changes reflect low-level data changes. For example, “a database row in a
shopping_cart_itemstable with an ID1was updated”.
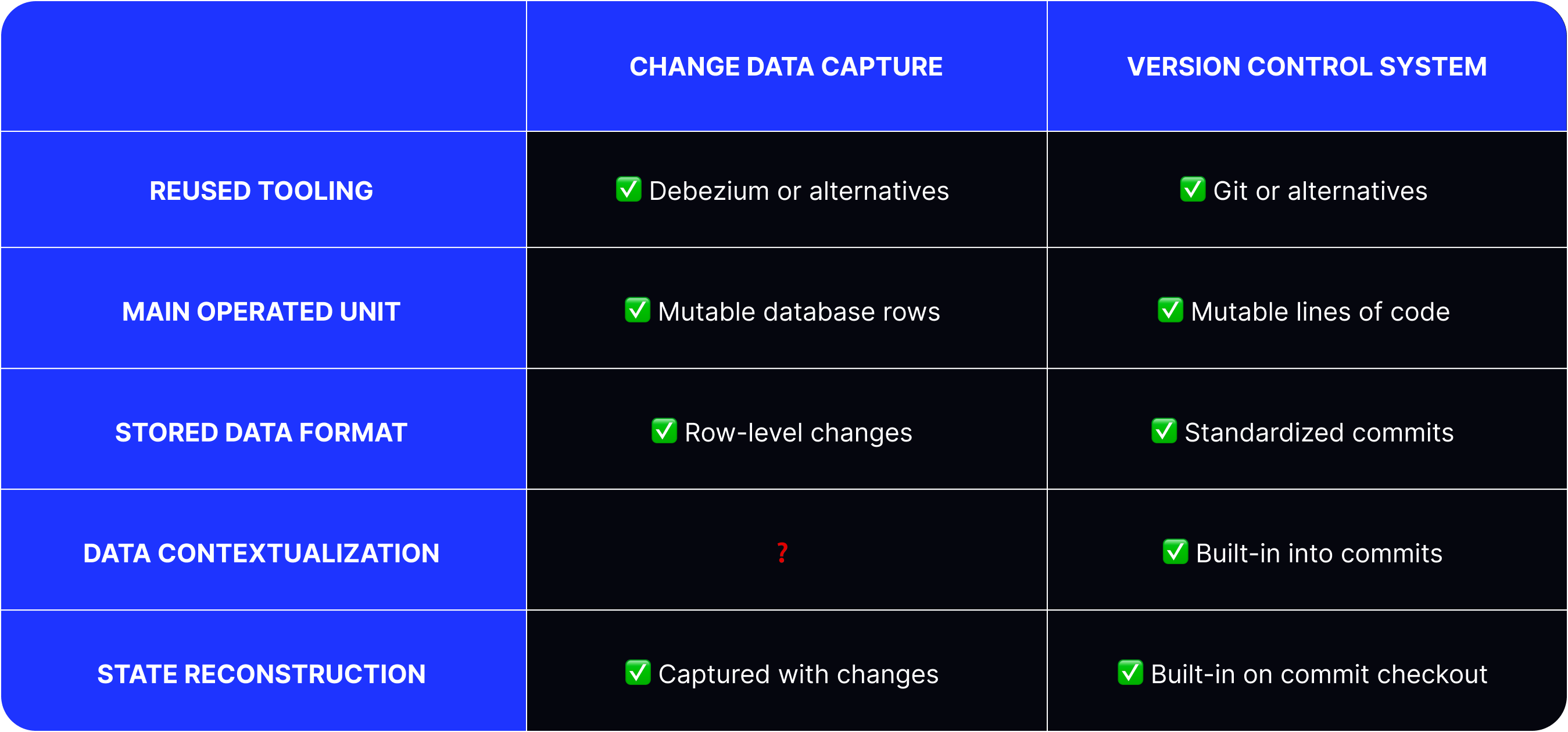
To bridge the gap and make database changes captured with CDC meaningful and consistent, we can use a couple of different approaches.
Approach 1: Outbox pattern with Change Data Capture
The Outbox pattern allows to atomically update data in a database and record messages that need to be sent in order to guarantee data consistency.
When performing regular database record changes, we can also insert event records in an “ephemeral” outbox table within the same transactions:
BEGIN;
UPDATE shopping_cart_items SET quantity = 2 WHERE id = 1;
UPDATE products SET in_stock_count = in_stock_count - 1 WHERE id = 123;
INSERT INTO outbox_events (event_type, entity_type, entity_id, payload) VALUES (...);
COMMIT;
Inserting events using the Outbox pattern
After the transaction completes, the domain-specific events can be reliably captured by CDC and permanently stored in an event store similarly to a traditional Event Sourcing approach.
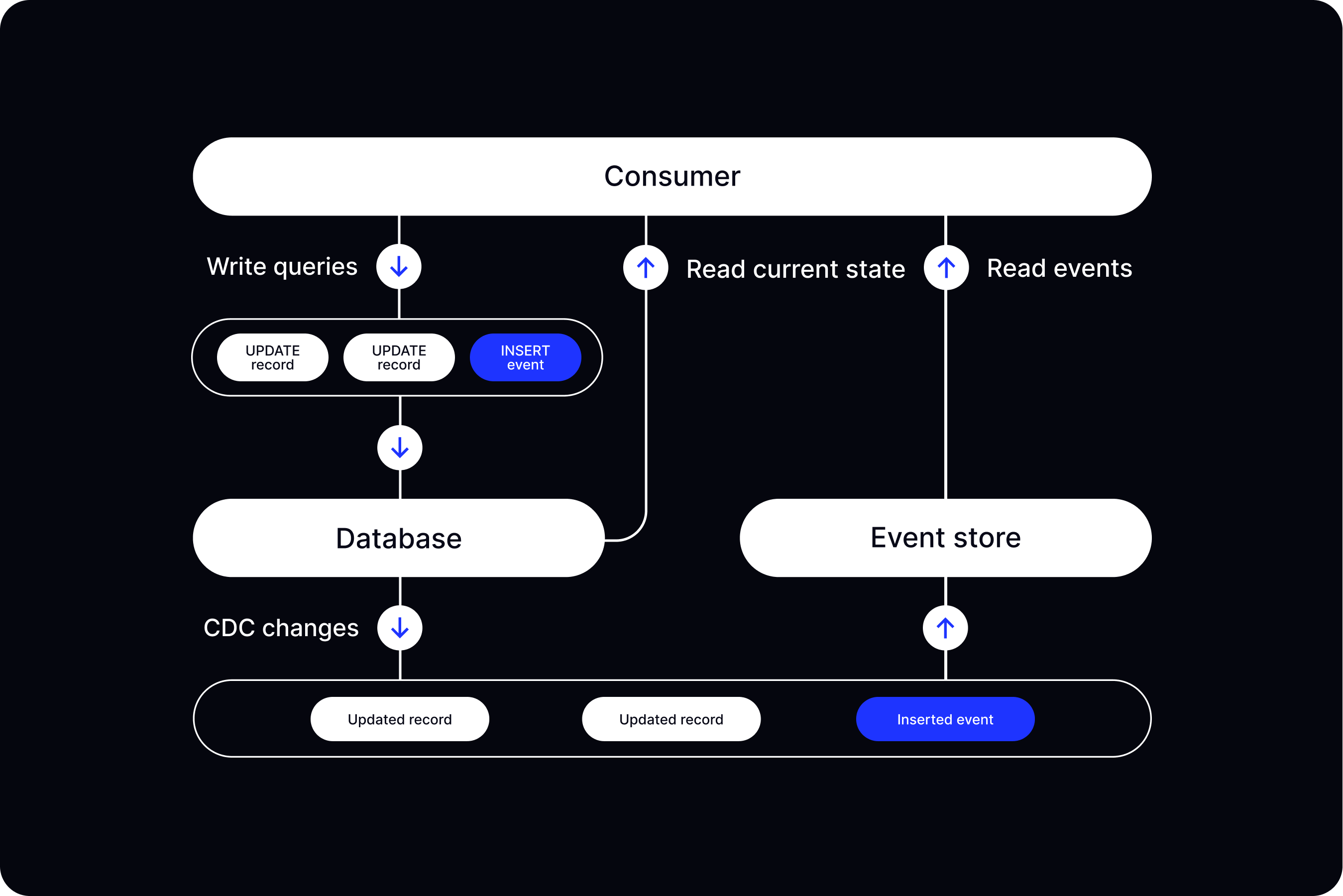
With this approach, we get the simplicity of a typical CRUD system and the benefits of an immutable and consistent append-only event store derived from data changes with CDC.
Approach 2: Contextualized Change Data Capture
Another slightly simplified and more practical approach is to contextualize data changes in CDC pipelines without making any modifications to the underlying data structure and database queries.
With a database like PostgreSQL, it’s possible to pass additional context with queries that can only be visible by a CDC system. Here is a simple code example written in JavaScript using Prisma ORM:
setContext({
// Event-related data
eventType: 'SHOPPING_CART_ITEM_QUANTITY_UPDATED',
entityType: 'SHOPPING_CART_ITEM',
entityId: 1,
quantity: 2,
// Additional context
userId: currentUser.id,
apiEndpoint: req.url,
});
await prisma.shoppingCartItem.update({
where: { id: 1 },
data: { quantity: 2 },
});
await prisma.products.update({
where: { id: 123 },
data: { inStockCount: product.inStockCount - 1 },
});After the changes are committed to the database, we can reliably capture them, stitch with the context, and store as audit trail records.
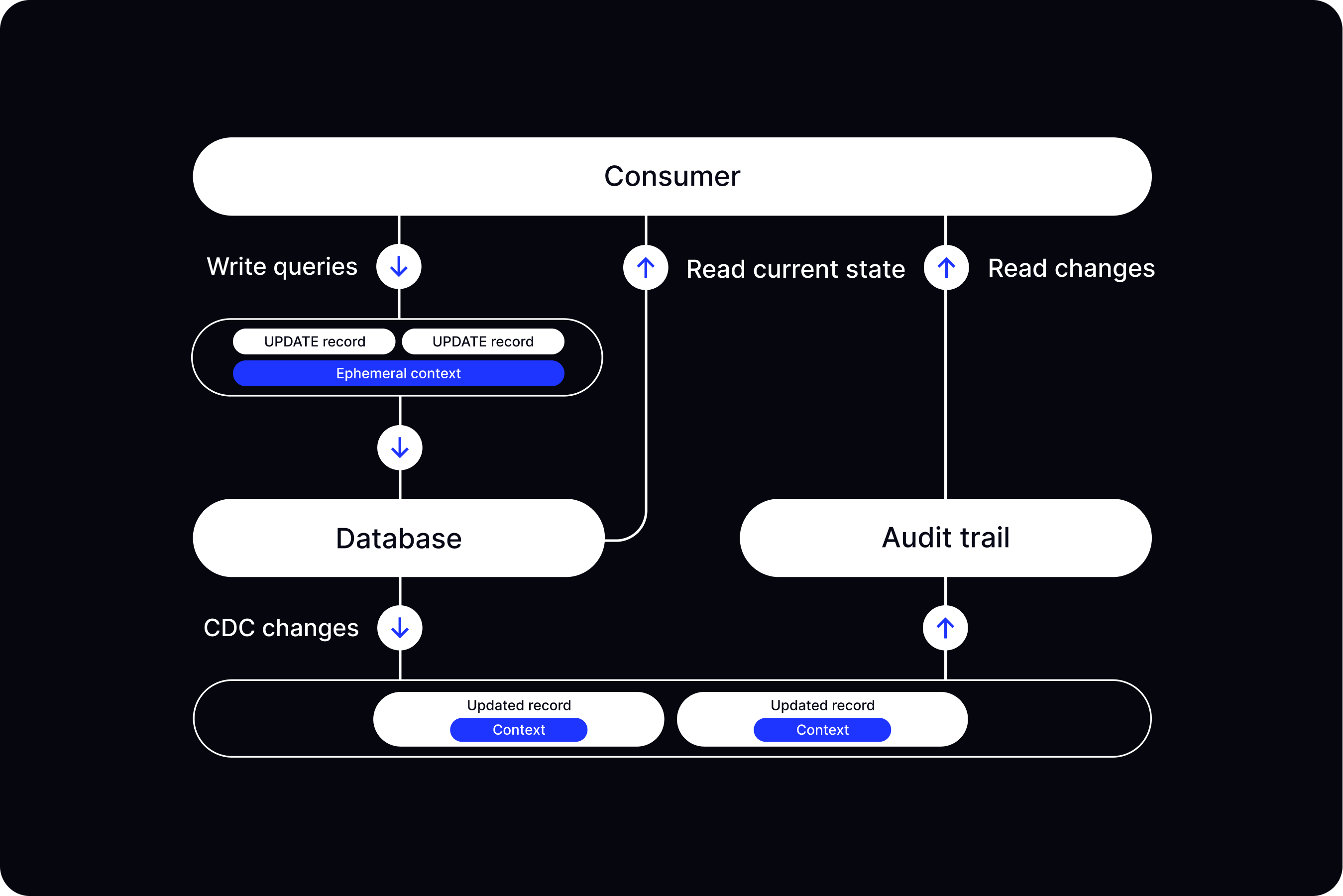
With this approach, we can continue using CRUD operations and store all event data as context in an immutable and reliable audit trail. This allows us, for example, to query all events by a particular “Shopping Cart Item” and see all underlying data changes made as part of these events.
Conclusion
It’s time to rethink Event Sourcing and stop trying to reinvent the wheel every time we want to implement it in our applications.
In some regulated industries like accounting there are already well-established industry standards for using Event Sourcing in a form of a double-entry bookkeeping system, such as a General Ledger.
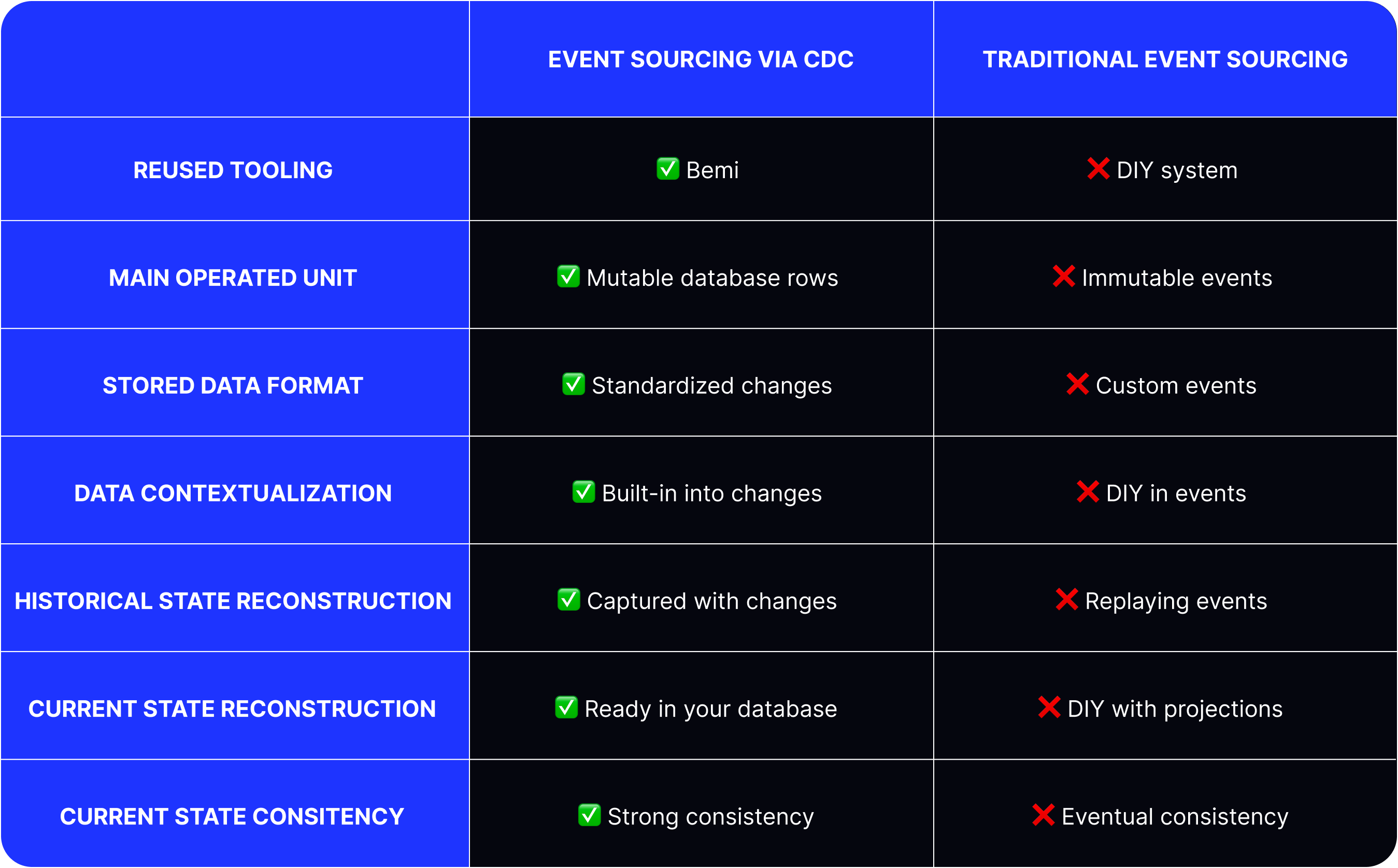
In 95% of other cases, you can get most of the Event Sourcing benefits by using Change Data Capture enriched with your domain-specific information. The Change Data Capture data design pattern allows to reliably track and record all data changes made in a database. This, in combination with the Outbox pattern or data change contextualization implemented in the application, allows you to achieve the Event Sourcing advantages mentioned at the beginning of this blog post.
This essentially flips the paradigm and allows deriving an immutable log of domain-specific events from regular database changes. Note that the described approaches are not meant to replace the business layer in your application. You still need to think about your domain design and implement it in your code.
About us
If you need help with event-sourcing your system, check out Bemi. Our solution can help you enable automatic data change tracking for your database in a few minutes, integrate it with your ORM for data change contextualization, and have a full audit trail automatically stored in a serverless PostgreSQL database.
For scaling a centralized Postgres data store, check out the BemiDB Github repo.