Data Analytics with PostgreSQL: The Ultimate Guide
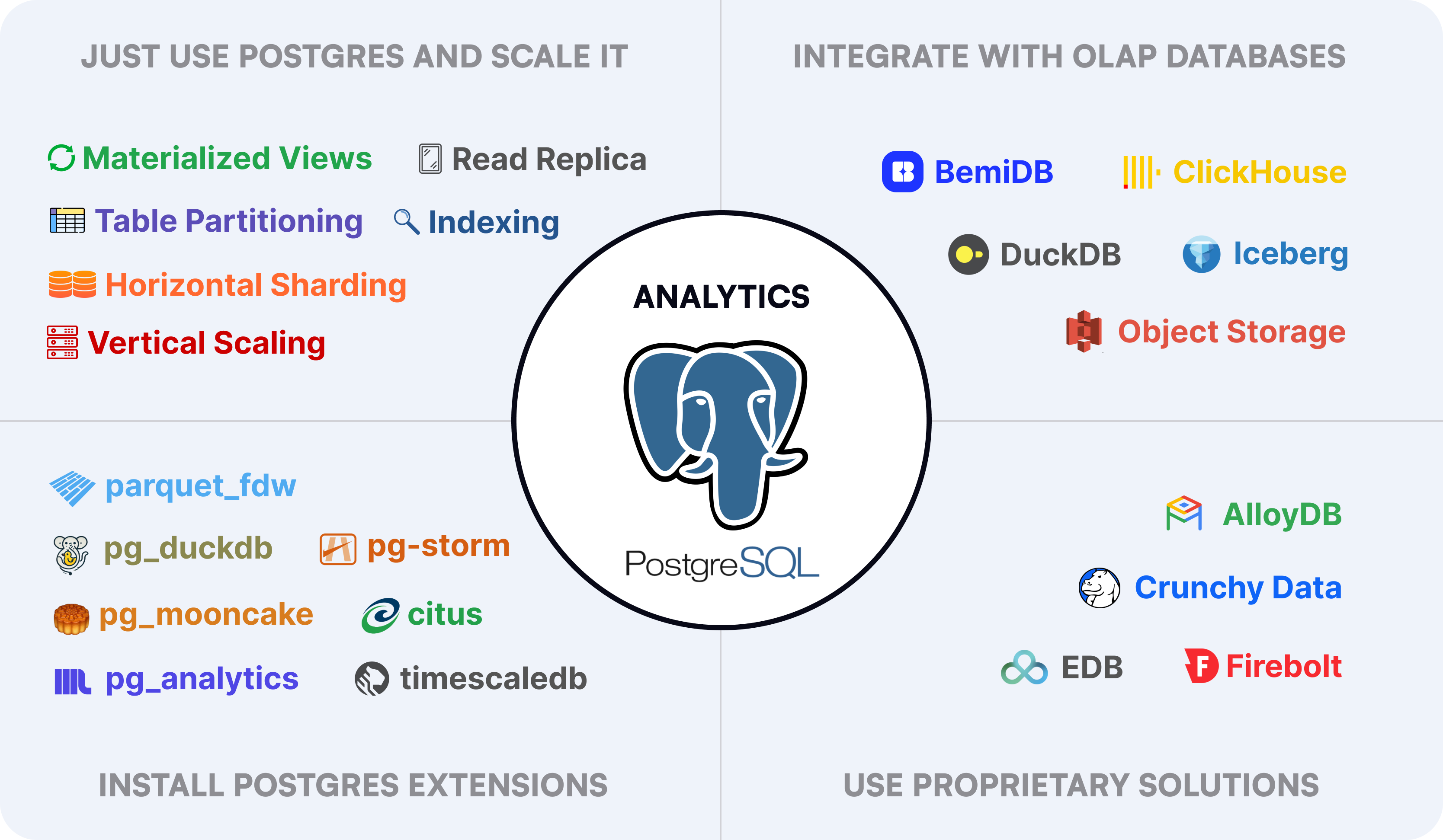

TL;DR
In this blog post, we will compare the main techniques and approaches for running data analytics with PostgreSQL:
- "Just use Postgres" and Scale It
- Indexes: choosing index types, multicolumn/partial/expression indexes
- Materialized Views: denormalization
- Table Partitioning: declarative partitioning
- Server Scaling: read replica, vertical scaling, horizontal sharding
- Install PostgreSQL Extensions
- Foreign Data Wrappers: columnar storage formats, Parquet, ETL
- Analytics Query Engines: vectorized execution, parallel execution on GPU, DuckDB
- Super Extensions: TimescaleDB and Citus
- Integrate with Analytics Databases
- BemiDB: read replica, vectorized engine and columnar storage, open table formats, Iceberg
- ClickHouse: PostgreSQL wire protocol, vectorized engine and columnar storage, logical replication
- Use Proprietary Solutions
- Google Cloud AlloyDB: hybrid transactional and analytical workloads
- EDB Analytics Accelerator: proprietary extension on PostgreSQL with replication
- Crunchy Data Warehouse: proprietary extensions on PostgreSQL
- Firebolt: forked ClickHouse with PostgreSQL dialect
Each of them has their pros and cons, so we will take a look at them and see which one may be the best for your use case.
"Just use Postgres" and Scale It
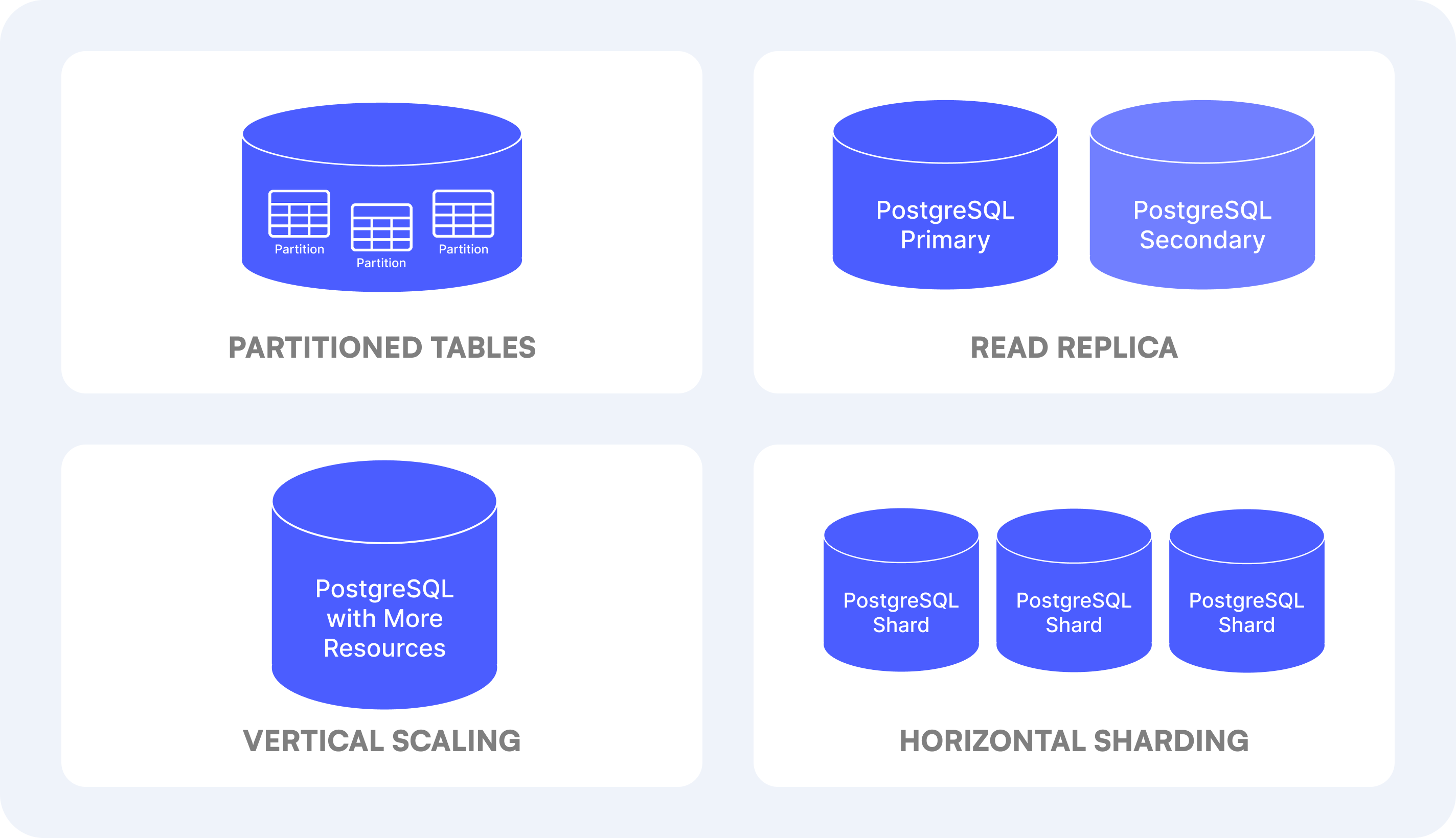
PostgreSQL is a highly flexible and powerful database. It simplifies your data stack by serving as a single transactional (OLTP) engine for a range of purposes—including full-text search, queueing, caching, and event streaming—while also being tunable for analytics (OLAP) queries. Below are the main built-in features.
To identify slow queries and their bottlenecks, we can use PostgreSQL's EXPLAIN ANALYZE which will show the sequential and index scans. Then, depending on the data structure and queries, you can choose an appropriate index type such as:
- B-tree for equality
=and range conditions like>or< - GIN for composite values like
JSONBorARRAY
See the full list of supported PostgreSQL index types and the optimized operators that work with them.
You can also create specialized indexes:
- Multicolumn index (for columns frequently used together in queries):
CREATE INDEX index_name ON table (column1, column2);- Partial index (for frequent filtering a subset of rows):
CREATE INDEX index_name ON table (column)
WHERE column > 1 AND column < 1000;- Expression index (for computed expressions or functions):
CREATE INDEX index_name ON table (LOWER(column));Denormalization is a strategy that allows improving read performance at the expense of adding redundant copies of data, similarly to a cache. One example is the use of PostgreSQL materialized views that can pre-compute and store query results in a table-like form for frequently accessed data.
CREATE MATERIALIZED VIEW summary_sales AS
SELECT seller_id, invoice_date, sum(invoice_amount) AS sales_amount
FROM invoices
WHERE invoice_date < CURRENT_DATE
GROUP BY seller_id, invoice_date;Creating a materialized view
PostgreSQL also allows adding indexes on materialized views and querying them like it is a regular table:
CREATE INDEX summary_sales_index
ON summary_sales (seller_id, invoice_date);
SELECT * FROM summary_sales
WHERE seller_id = 1 AND invoice_date = '2025-01-01'Creating an index and querying a materialized view
Partitioning is a technique that allows splitting a large table into smaller physical ones called partitions. This helps improve query performance by scanning only relevant partitions instead of the entire large table.
CREATE TABLE invoices (issued_on DATE NOT NULL)
PARTITION BY RANGE (issued_on);
CREATE TABLE invoices_2025_01 PARTITION OF invoices
FOR VALUES FROM ('2025-01-01') TO ('2025-02-01');
CREATE TABLE invoices_2025_02 PARTITION OF invoices
FOR VALUES FROM ('2025-02-01') TO ('2025-03-01');
Declarative partitioning of a table by range
Native PostgreSQL declarative partitioning treats the partitioned table like a “virtual” one that delegates reads/writes to the underlying partitions:
-- Stores the row into invoices_2025_01
INSERT INTO invoices (issued_on) VALUES ('2025-01-31');
-- Stores the row into invoices_2025_02
INSERT INTO invoices (issued_on) VALUES ('2025-02-01');
-- Selects the rows from invoices_2025_01
SELECT * FROM invoices WHERE issued_on = '2025-01-31'Writing and reading a partitioned table
Server Scaling
There are a few server scaling options available for PostgreSQL when it comes to running analytical workloads.
- Read replica. To offload read queries from the primary server, you can set up one or more PostgreSQL read replicas.
- Vertical scaling. This is the most straightforward approach. When a server can't handle the load, consider upgrading the hardware and giving it more resources.
- Horizontal scaling. Another option is to use sharding by distributing data across multiple servers called shards. For example, you can implement application-level logic to determine which shard to access when reading or writing data.
PostgreSQL Pros
- Powerful general-purpose database transactional database (OLTP) that can handle basic analytical workloads (OLAP) out of the box.
- "Just use Postgres" allows keeping the data stack as simple as possible without adding additional tools and services.
PostgreSQL Cons
- Creating indexes tailored for specific queries negatively impacts the "write" performance for transactional queries and resource usage.
- Materialized views as a "cache" require manual maintenance and can become increasingly slow to refresh as the data volume grows.
- Table partitioning is a leaky abstraction that doesn't perfectly encapsulate the details and doesn't play nice with triggers, constraints, etc.
- Scaling up servers often is a short-term solution that buys some time but doesn't solve the underlying performance issues.
- Horizontal scaling using sharding significantly increases the complexity of the database architecture and introduces engineering and operational overhead.
- Continuously spending a lot of engineering resource to gain meaningful long-term performance improvements.
- Further tuning and optimization may not be possible if executing various ad-hoc analytical queries.
Install PostgreSQL Extensions
PostgreSQL has a rich ecosystem of extensions that enhance its functionality in different areas, including data analytics. There are a few different approaches that these extensions take, which can be grouped into the categories described below.
Foreign Data Wrappers
One of the most popular data storage file formats used in analytics is Parquet. Think of it as "CSV on steroids for analytics". Here are its key features:
- Columnar storage format with data organized by columns rather than rows
- Excellent compression due to storing similar data together in columns
- Strongly typed schema with explicitly defined types for each column
The common pattern is extracting data from PostgreSQL (or other data sources), transforming it if necessary, and loading it, for example, in Parquet format to S3. This extract, transform, and load process is called ETL.
To query Parquet files using PostgreSQL, you can use foreign data wrappers (FDW). This is a mechanism that allows to access data stored outside a database as it is stored in a local table. The most popular PostgreSQL extensions for Parquet are:
- parquet_fdw for reading Parquet files from a local file system
- parquet_s3_fdw for reading Parquet files from S3-compatible object storage
Here is an example how these foreign data wrappers can be used:
-- Set up the extension
CREATE EXTENSION parquet_s3_fdw;
CREATE SERVER parquet_s3_server FOREIGN DATA WRAPPER parquet_s3_fdw;
-- Create a foreign table
CREATE FOREIGN TABLE invoices (issued_on DATE NOT NULL)
SERVER parquet_s3_server
OPTIONS (filename 's3://bucket/dir/invoices.parquet');
-- Querying data from a Parquet file
SELECT issued_on FROM invoices;Querying Parquet data using a foreign data wrapper
Analytics Query Engines
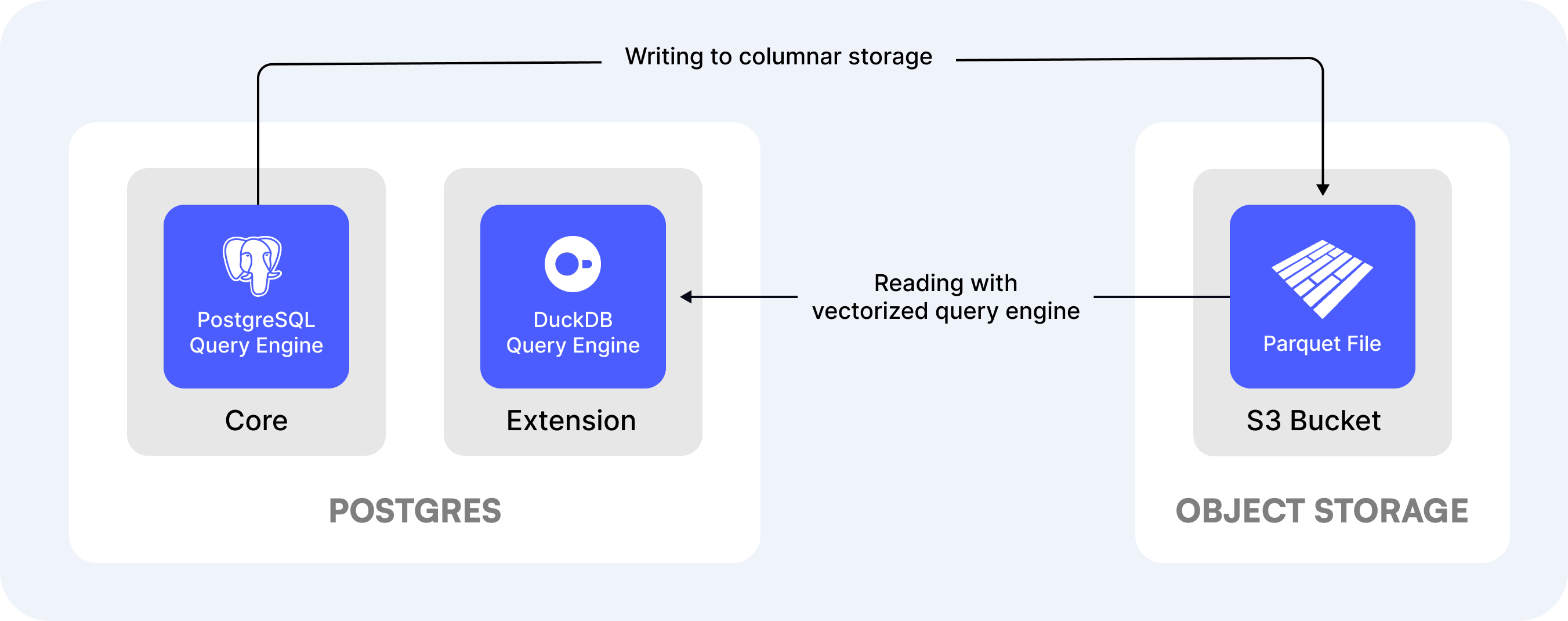
To get the best performance when running analytical workloads, using columnar storage format like Parquet is often not enough because the PostgreSQL query engine still processes each row sequentially.
Enter DuckDB, a columnar-vectorized query execution engine. Think of DuckDB as "SQLite for analytics" that is lightweight and can store all its data on a disk or in memory. Here are its main key features:
- It uses a columnar-verctorized engine, which supports parallel execution and can efficiently process large batches of values, a.k.a. vectors.
- It is a single-binary program without any external dependencies that can run on all operating systems or can be embedded into another program.
- It provides a universal SQL access to various data types such as Parquet, CSV, JSON, and sources such as remote S3 buckets, API endpoints, Excel.
- And similarly to PostgreSQL, it also supports extensions to improve its core functionality.
DuckDB version 1.0 was released in 2024, and since then many new PostgreSQL extensions that embed DuckDB or build their own query engines started being developed. Here are some of them:
- pg_duckdb embeds DuckDB and can query Parquet files from object storage
- pg_mooncake embeds DuckDB and uses columnar storage within PostgreSQL
- pg_analytics embeds DuckDB and uses foreign data wrappers to read from S3
- pg-strom uses a parallel execution engine that can leverage GPU cores
-- Set up the extension
CREATE EXTENSION pg_duckdb;
-- Querying data from a Parquet file
SELECT issued_on FROM read_parquet('s3://bucket/dir/invoices.parquet');Querying Parquet data using pg_duckdb extension
Super Extensions
There are some extensions that significantly alter how PostgreSQL works. Such extensions are sometimes called "super extensions" and very often installed on a dedicated PostgreSQL server.
These extensions are not designed for data analytics, but some of their features can still improve PostgreSQL query execution and performance. Here are some of the extensions:
- timescaledb is designed to turn PostgreSQL into a time-series database. It can automatically partition tables by time-columns, use hybrid row-columnar store, and refresh materialized views incrementally.
- citus is designed to turn PostgreSQL into a distributed database. It can automatically shard tables across servers and use columnar storage for compression and query performance.
Extensions Pros
- Adding new features to PostgreSQL while keeping everything under one roof.
- Variety of open-source extensions that can provide great flexibility and customization to your PostgreSQL.
- Querying data stored in compressed columnar format and/or bringing an analytical query engine to improve performance.
Extensions Cons
- Performance overhead when running analytical queries within the same PostgreSQL that can negatively affect transactional queries.
- Very limited support for installable extensions in managed PostgreSQL services. For example, here is the AWS Aurora allowlist.
- Increased dependency management and maintenance complexity when using extensions or upgrading PostgreSQL/extension versions.
- Manual data syncing and data mapping using ETL pipelines or within PostgreSQL from native row-based storage to columnar storage for best performance.
- Some TimescaleDB features are not available under an open-sourced license: incremental materialized views, compression, and query optimizations.
Integrate with Analytics Databases
There are a few OLAP databases that can integrate with PostgreSQL databases and are also compatible, so you can use PostgreSQL tools like database drivers and adapters as usual.
Disclaimer: I’m a BemiDB contributor. And even though I’m biased and want more people to use BemiDB as a simple solution to the PostgreSQL data analytics problem, I’ll try to be as objective as possible.
BemiDB is a read replica optimized for analytics. It connects to a PostgreSQL database, automatically syncs data into a compressed columnar storage, and uses a Postgres-compatible analytics query engine to read the data.
Here are its main key features:
- Single binary that can be run on any machine. The compute is stateless and separated from storage, making it easier to run and manage.
- Embeds DuckDB to improve performance, a columnar-vectorized query execution engine optimized for analytical workloads.
- Uses an open columnar format for tables with compression. The data can be stored either on a local file system or on S3-compatible object storage.
- Postgres-integrated, both on the SQL dialect and table data level. I.e., all
SELECTqueries executed on a primary PostgreSQL server can be ported to BemiDB as is.
# Sync data from PostgreSQL
bemidb --pg-database-url postgres://localhost:5432/dbname sync
# Start BemiDB
bemidb start
# Query BemiDB as a PostgreSQL read replica
psql postgres://localhost:54321/bemidb -c "SELECT COUNT(*) FROM table_from_postgres"Running BemiDB as a read replica optimized for analytics
We've already described Parquet data format and its benefits. The next evolutional approach is using open table formats, such as Iceberg that is used by BemiDB under the hood. These formats use Parquet files to store data in compressed columnar format and stitch them together using metadata files according to format specifications. This helps adding smaller Parquet data files incrementally instead of fully rewriting files on every data change.
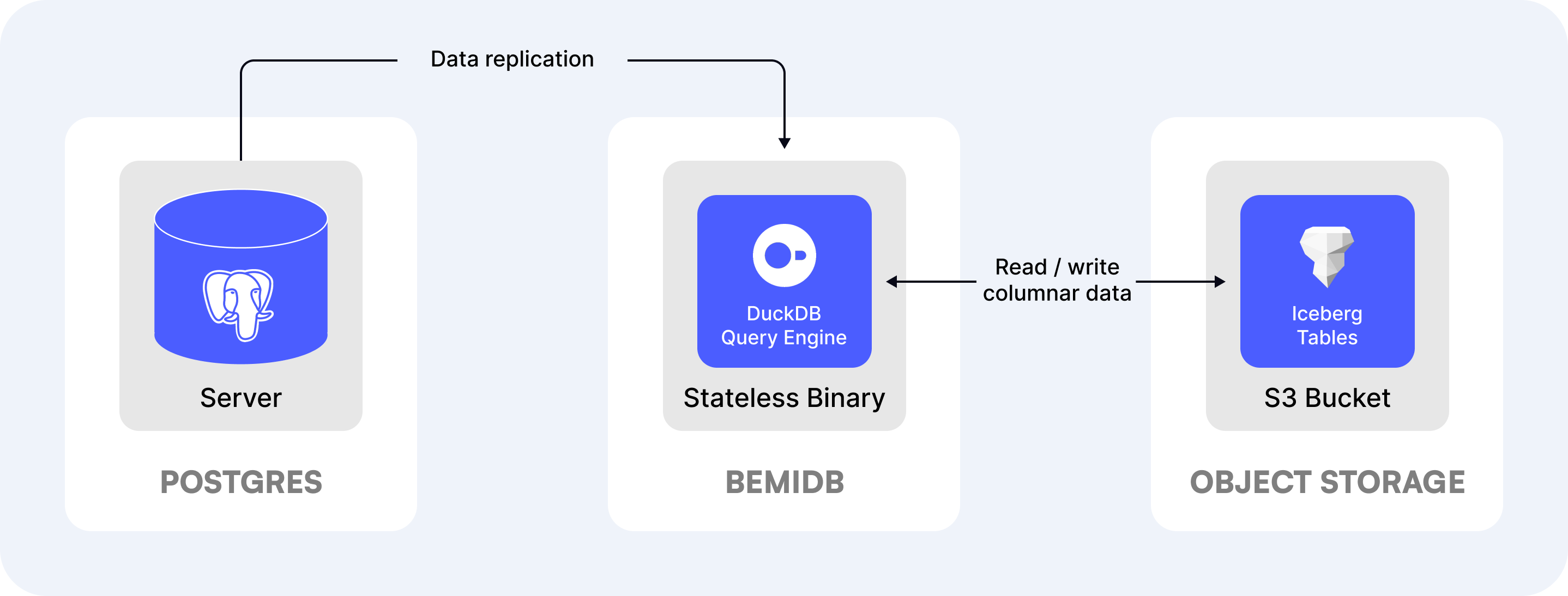
With open table formats like Iceberg, in addition to query performance benefits, it's possible to achieve things that are not possible with PostgreSQL. For example, data interoperability across different databases/tools/services and schema evolution/time travel enabling access to historical versions.
ClickHouse is a column-oriented database designed for real-time analytics. The company recently acquired PeerDB that allows syncing data from PostgreSQL into ClickHouse in real-time. It also has some basic PostgreSQL compatibility allowing you to connect and run ClickHouse SQL queries via the PostgreSQL wire protocol.
Here are its main key features:
- Distributed processing across multiple servers in a cluster enabling horizontal scalability.
- Vectorized query execution engine optimized for analytical workloads.
- Columnar storage that enables data compression and improved query performance.
- ClickHouse is optimized for inserting large batches of rows, usually between 10K and 100K rows.
PeerDB that behaves like an ETL tool that connects to PostgreSQL databases using logical replication and decoding. The transformations can be performed using custom Lua scripts.
Analytics Databases Pros
- The best performance tailored specifically for analytical workloads.
- Integrate with PostgreSQL databases and replicate data into a scalable columnar storage format. Minimal impact on PostgreSQL performance, resource usage, and internal configuration.
- BemiDB consists of a single binary allowing to easily run and manage an optimized for analytics PostgreSQL read replica.
- ClickHouse allows batch data inserts directly, bypassing PostgreSQL.
Analytics Databases Cons
- They are not PostgreSQL and don't support many PostgreSQL-specific features or extensions.
- Increased system complexity with extra server processes running in addition to PostgreSQL.
- BemiDB doesn't support direct Postgres-compatible write operations (yet), so it can only work as a read replica.
- ClickHouse is quite different from PostgreSQL and OLTP databases in many ways: different SQL dialect, limitations on data mutability, no support for ACID (atomicity, consistency, isolation, durability), and many others.
Use Proprietary Solutions
Due to PostgreSQL's popularity, many companies started building their custom proprietary solutions for analytics either on top of PostgreSQL or making them Postgres-compatible.
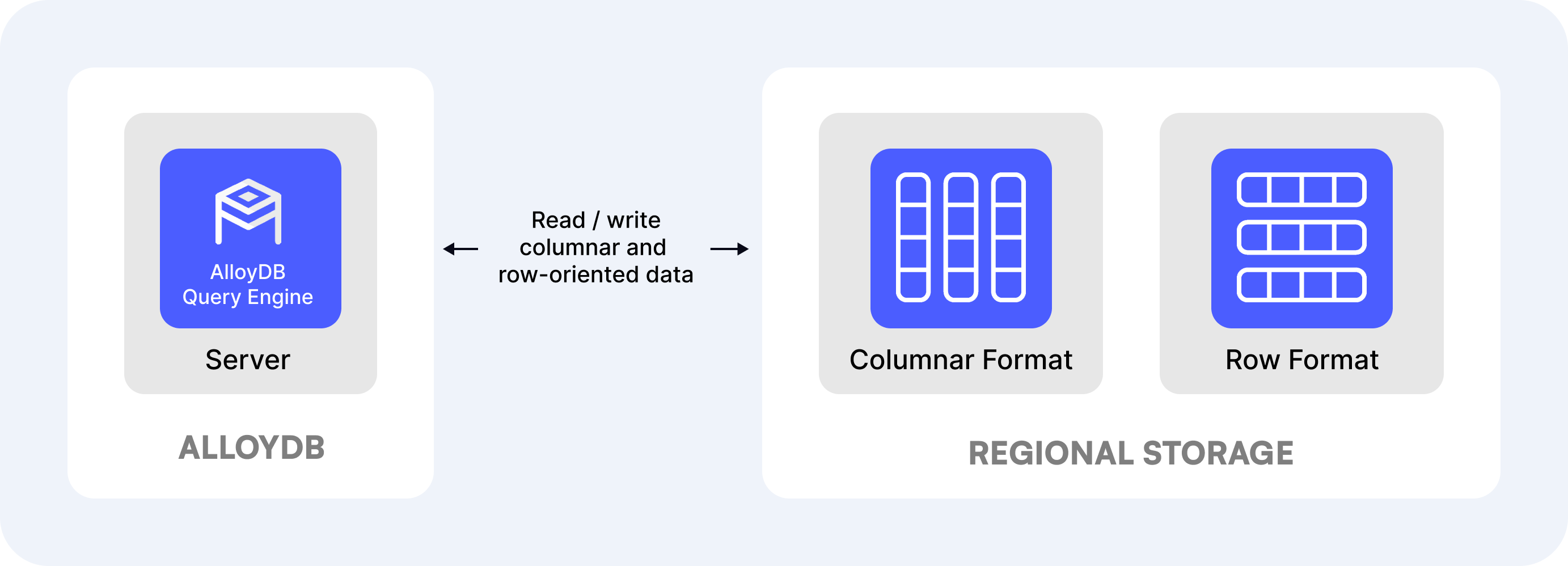
AlloyDB is a managed PostgreSQL-compatible database for hybrid transactional and analytical workloads (HTAP). It can replace PostgreSQL for transactional queries and also deliver good performance for analytical queries.
Here are its main features:
- Enhanced query processing layers in PostgreSQL kernel for performance and shared storage in a region.
- Embeds a proprietary vectorized engine and storage with an additional columnar format.
- Query planner that automatically chooses an execution fully on columnar data, fully on row-oriented data, or a hybrid of the two.
- Has a downloadable version called AlloyDB Omni that can also run on AWS and Azure in a Docker container.
EDB (a.k.a. EnterpriseDB) Postgres AI is a data platform for both transactional and analytical workloads. The analytics product is powered by PostgreSQL and the proprietary extension called PGAA.
Here are the main analytics features:
- Vectorized query engine optimized for columnar data formats.
- Tiered storage, with hot data on a disk and cold data in object storage in open table formats.
- Storage and compute separation with dedicated PostgreSQL replicas for analytical queries.
Crunchy Data is a company that specializes in providing services, support, and solutions for PostgreSQL. The company released Crunchy Data Warehouse in 2024, an analytics database built on PostgreSQL.
The main features include:
- The latest versions of PostgreSQL with proprietary extensions.
- Integrated DuckDB query engine by delegating parts of the query to it for vectorized execution.
- S3 for storage with an Iceberg table format that can be queried with tools like Apache Spark.
Firebolt is a cloud data warehouse. It started by forking ClickHouse to implement better storage and compute decoupling, along with other improvements. In 2024, they added Postgres SQL dialect compatibility.
- Vectorized query execution engine, ACID compliant.
- Proprietary columnar data format and tiered storage in memory, local SSD, and S3.
Proprietary Solutions Pros
- Fully managed cloud data warehouses optimized for analytical workloads.
Proprietary Solutions Cons
- Vendor lock-in and limited control over the source code and data.
- Very limited or no support at all for installable extensions. For example, here is the GCP AlloyDB allowlist.
- Crunchy Data and Firebolt require manual data syncing using ETL pipelines or within PostgreSQL from native row-based storage to columnar storage.
- Can be more expensive compared to other alternatives.
Conclusion
There is a wide variety of options for handling data analytics with PostgreSQL.
- Just using PostgreSQL and scaling it can be a great starting point for simpler analytical needs initially, allowing to keep the data stack simple.
- With enough PostgreSQL expertise and access to custom extensions, installing them can help improve analytical performance within PostgreSQL.
- If you don't want to spend time tuning PostgreSQL and all you need is a simple read replica optimized for analytics, then BemiDB is the best choice.
- If you deal with many terabytes of mostly append-only data and don't mind switching to another SQL dialect, then ClickHouse is a great choice.
- And if you already host PostgreSQL on platforms like GCP or EDB, then choosing their analytics solutions can reduce the number of data providers.
Check out the BemiDB GitHub repo if you want to give it a shot. And subscribe to our blog if you want to learn more about PostgreSQL and data analytics.